
Paper Reading: Embodied AI 10
从一些 Embodied AI 相关工作中扫过。
ALOE#
Action chunk 级 TD Bootstrap 的 VLA Offline RL
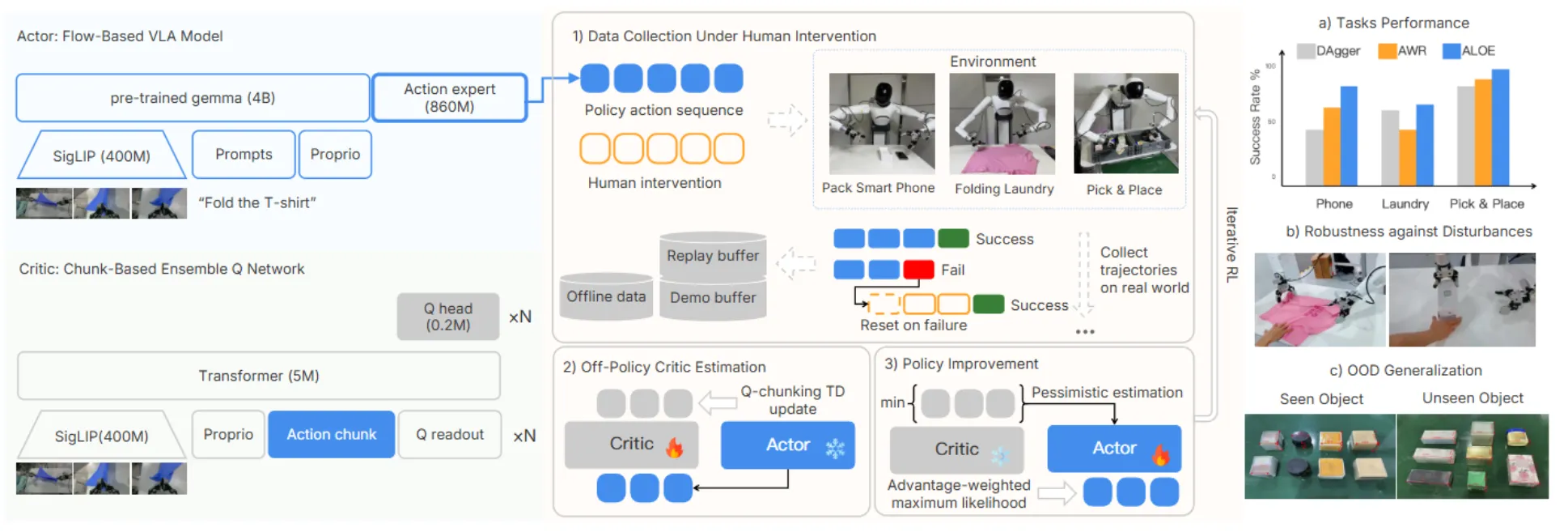
ALOE 针对 VLA 常用的 action chunk 输出做 offline RL,核心是在 chunk 粒度做 TD bootstrap 而不是只看最终任务成败。从流程上来说还是比较简单的,还是先进行 warmup,然后 rollout 一些数据,之后训练 critic。本身这里 RL 的方式其实就是用 Reward 去给 Action 信号的监督进行了加权,也就是类似于 Diffusion-NFT 的做法。里面还有一些 trick,值得一看。
DM0#
多 Stage CoT Pi-like VLA
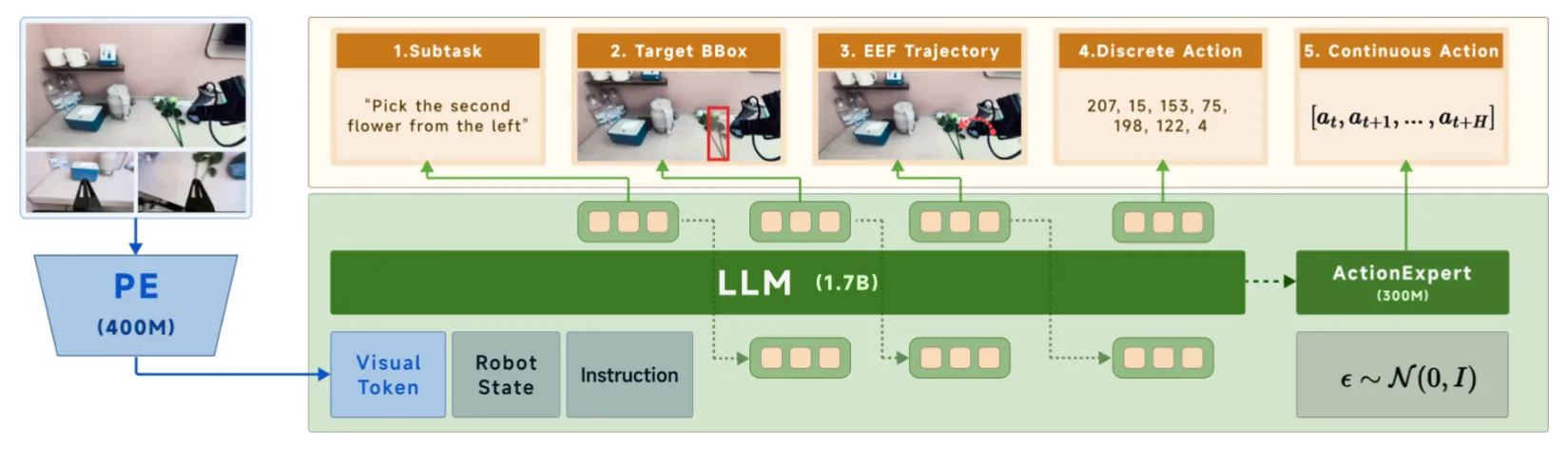
DM0 本身的思路如图所示,其实就是接受 VL 输入之后进行多轮推理,然后之后输出 Action;另外一种模式就是不推理。本身 DM0 在训练的时候会 Co-training,并且有很多的 VQA 以及各种数据拼盘,本身在他们自家 RoboChallenge Benchmark 上面性能也还算不错。
RynnBrain#
2B / 8B / 30B 的具身时空 VLM 基础模型
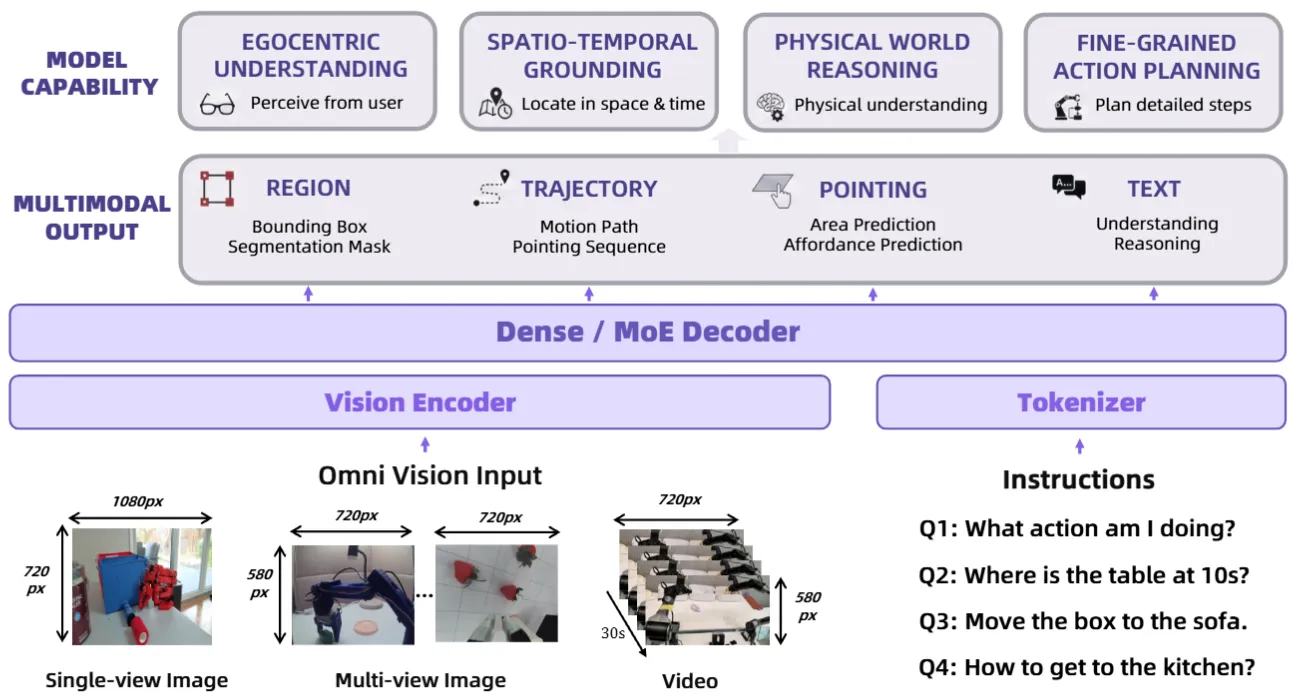
RynnBrain 是一个 open-source 具身时空 VLM 基础模型,提供 2B / 8B / 30B 三个档位,覆盖 ego 理解、空间时间定位、物理推理、物理感知规划四件事。属于 RoboBrain 2.5 / Thinker 同一类基础模型。相关论文评分按照惯例,具体细节可以看论文内容。
FUTURE-VLA#
同时预测 Action 和 Visual Token 的 OpenVLA-like VLA
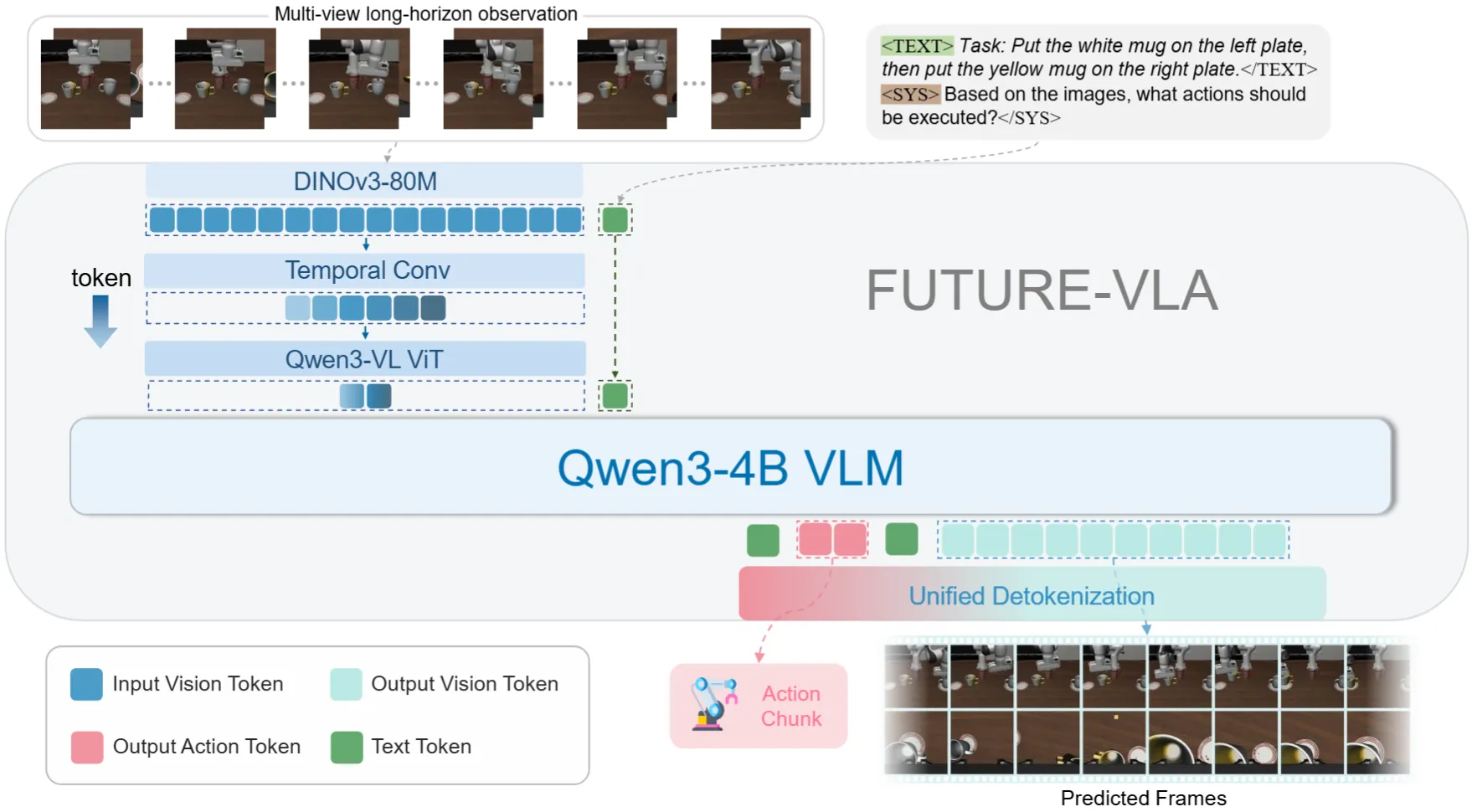
FUTURE-VLA 主要实现的是 AR 来 unified 预测未来以及 action,同时对于 encoder 进行了一些压缩,使得可以接受比较长的历史输入。然后对于输出,对于 Action 使用 FAST token,对于 Visual 使用 TiTok 的 Token,然后进行 AR。本身思路上比较清晰,但是选择 Qwen 而不是一些 UMM,本身感觉还是比较迷惑的,可能还是从拟合以及基模性能的角度来理解会合理一些。
DreamZero#
DiT 预测世界 + 动作的 World Action Model
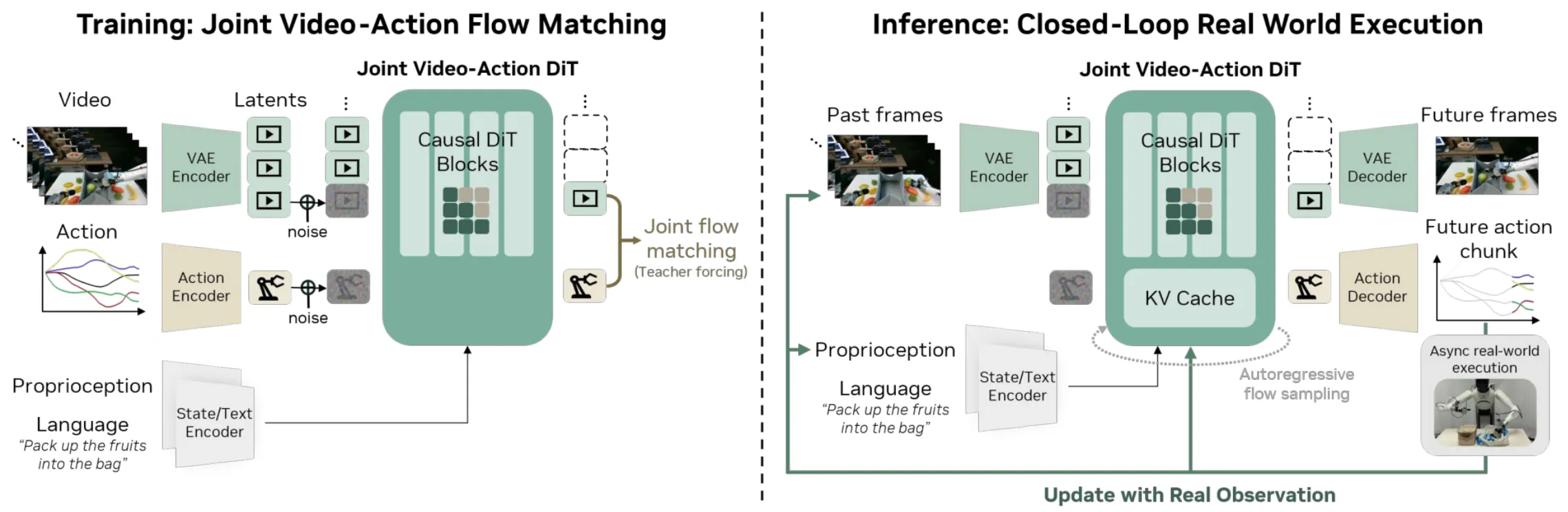
DreamZero 本身是和 Cosmos Policy 同思路的 WM-VLA 模型,也就是俗称的 WAM。本身的思路比较类似,但是预测的内容更加收敛,直接使用 14B DiT 预测 Future Frame 以及 Action,没有像是 Lingbot-VA 一样解耦 IDM 出来而是直接端到端,并且使用 teacher forcing 训练。本身里面还包括了一些加速的处理以及其他细节,值得一看。本身模型可以在一定程度上实现了 Zero-shot,虽然说动作依然不是特别丝滑,但是未来可期。
EgoScale#
20K 小时 Ego 视频预训 + 两阶段迁移到 22DoF 灵巧手
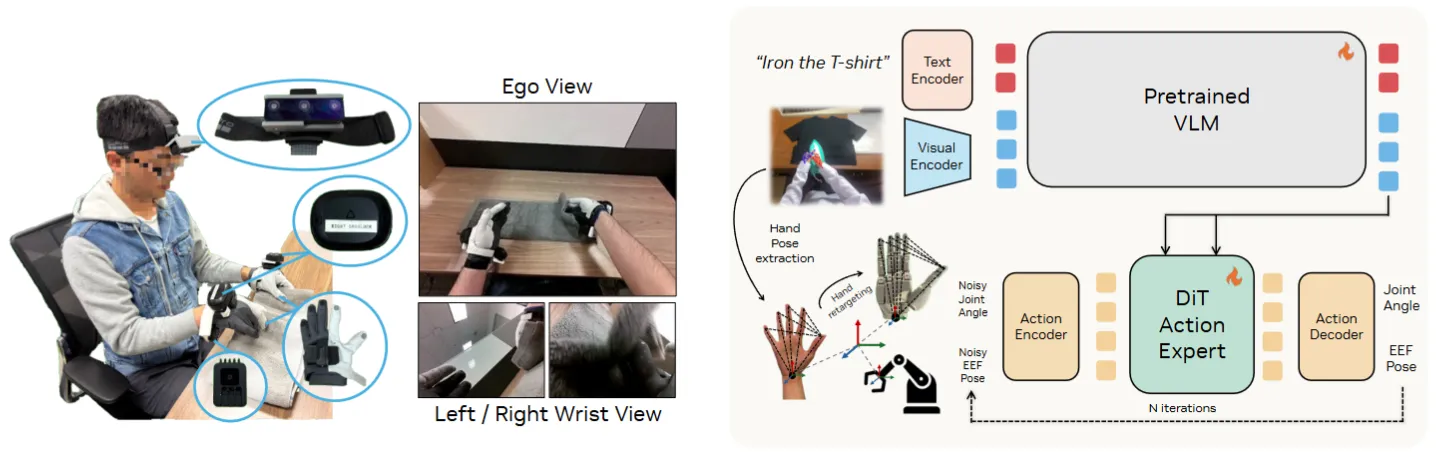
EgoScale 用 20,854 小时带 action 标注的 ego 视频预训一个 VLA,再用轻量的人-机对齐 mid-training 迁到 22 DoF 灵巧手,mid 冻结视觉-语言主干网络,仅更新视觉编码器和 DiT 动作专家,之后可以直接后训练。本身的模型结构和 GR00t 比较类似,并且对于不同的本体使用不同的 MLP 来适配。效果上还算不错,作为利用 Ego Video 的工作很值得参考。
HALO#
文本 CoT / 视觉 subgoal / 动作三专家 MoT VLA
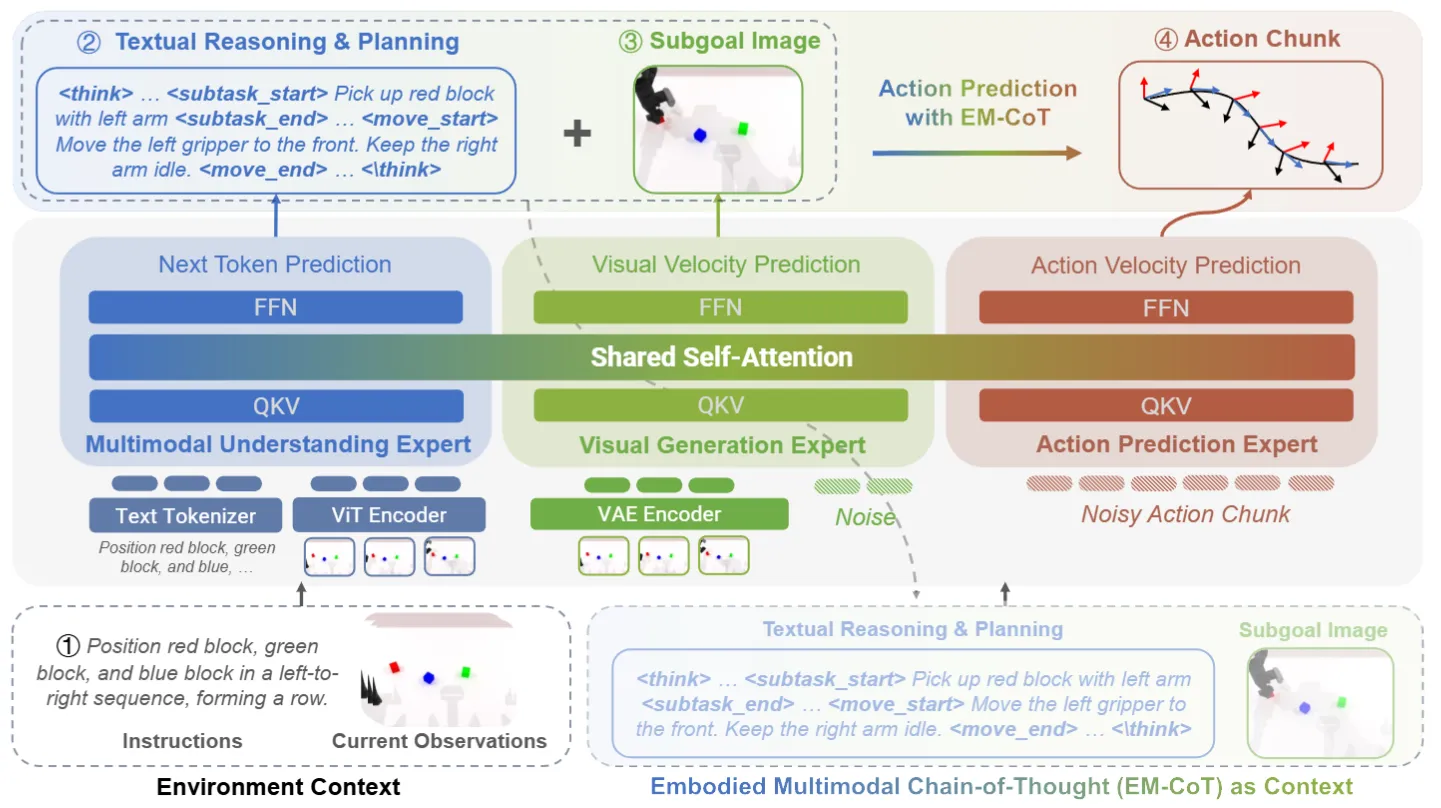
HALO 是 MoT 架构,把 textual reasoning、visual subgoal 预测、action 预测分给三个 expert。和 InternVLA-A1、Motus、F1-VLA 以及 BagelVLA 等在思路上同质。
LeRobot#
HuggingFace LeRobot 技术报告
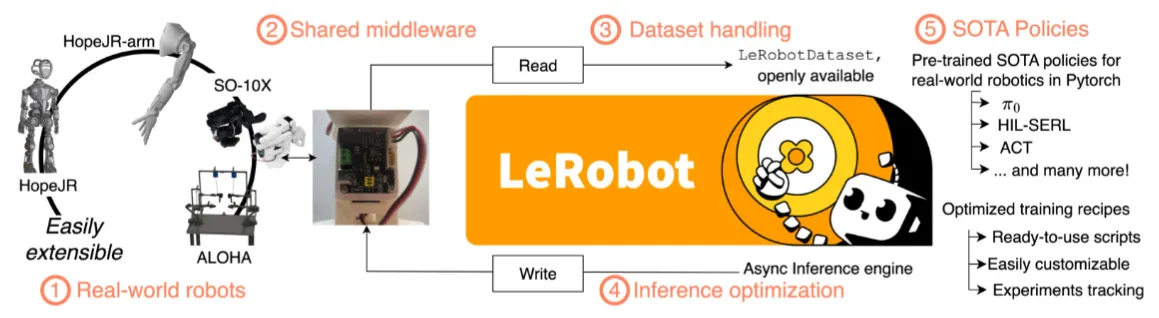
LeRobot 是 HuggingFace 侧的开源机器人学习栈官方技术报告,覆盖从底层电机控制 middleware 到数据集采集 / 管理以及多种 SOTA 算法的集成。究其根本,LeRobot 数据集还是比较流行的,但是似乎其他部分的完善度有所欠缺,社区也并没有在广泛使用。不过还是值得一看。
WoG#
在 condition space 里做世界建模的 VLA
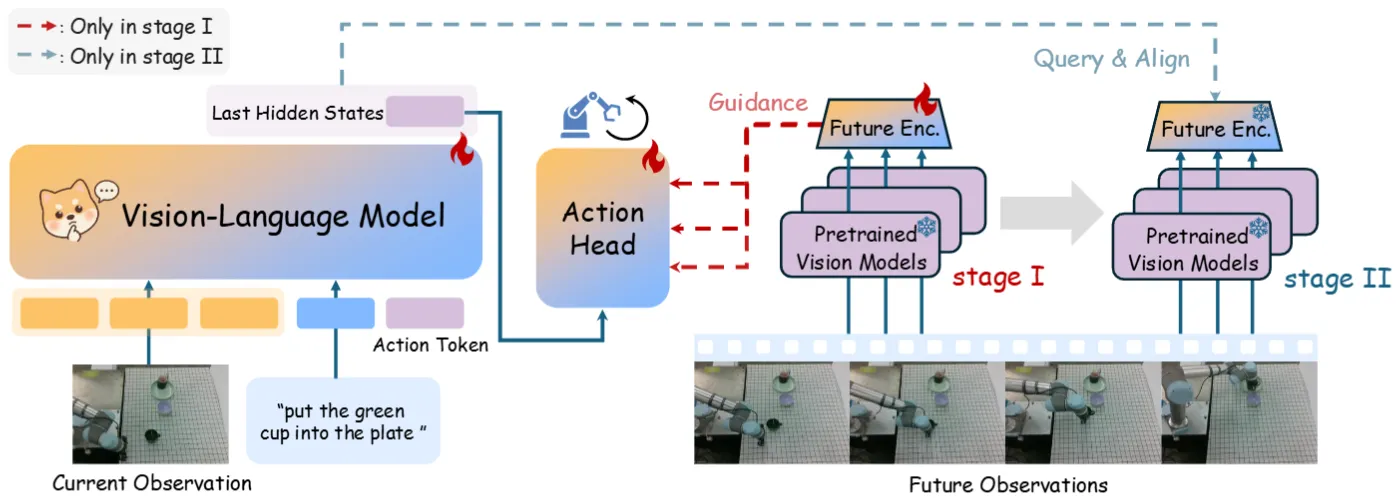
WoG 本身是 Pi-like 的模型,大的框架依然是 VLM 生成潜在表示,并且作为 DiT 输入,然后之后用 Q-former 将未来的 Visual Feature(使用 DINOv2 和 Wan VAE)作为 Condition 也加进去,作为第一阶段训练;之后在第二阶段,将潜在表示与 Visual Feature 对齐,并且生成动作。本身 WoG 的两阶段还是比较类似于课程学习的风格,同时尝试利用了一些人类数据,大概可以提升 10 个点左右。本身思路还算有趣,值得一看。
ACE-Brain-0#
三段式训练的空间智能基础模型
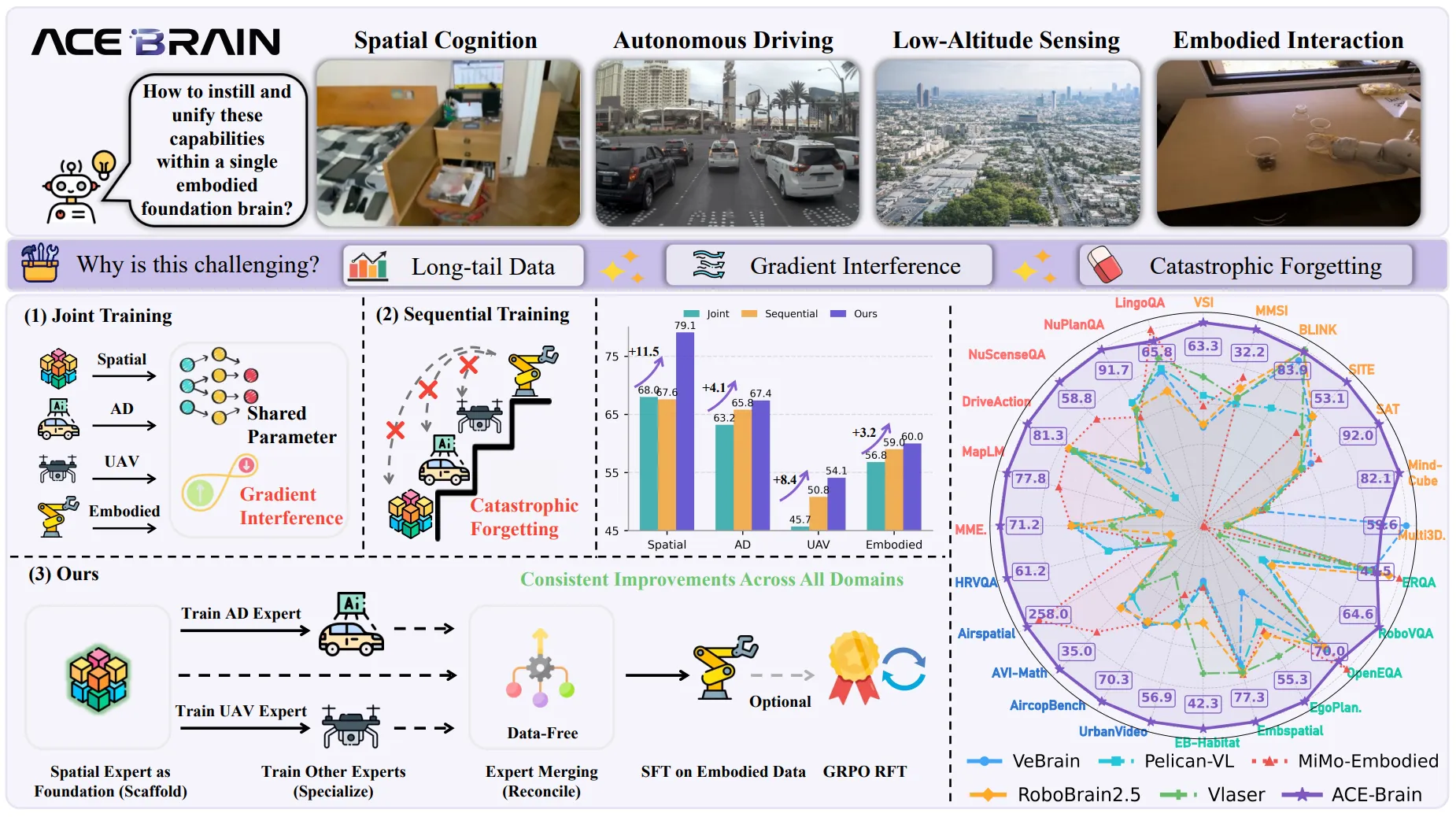
ACE-Brain-0 想一统驾驶 / 机器人 / UAV 三域,用 Scaffold-Specialize-Reconcile 三段式:先建共享空间 foundation,再训领域专家,最后无数据模型合并。依然是具身大脑,按照惯例评分,详细可以见论文内容。
MEM#
短时视频记忆 + 长时文本记忆的多尺度具身记忆
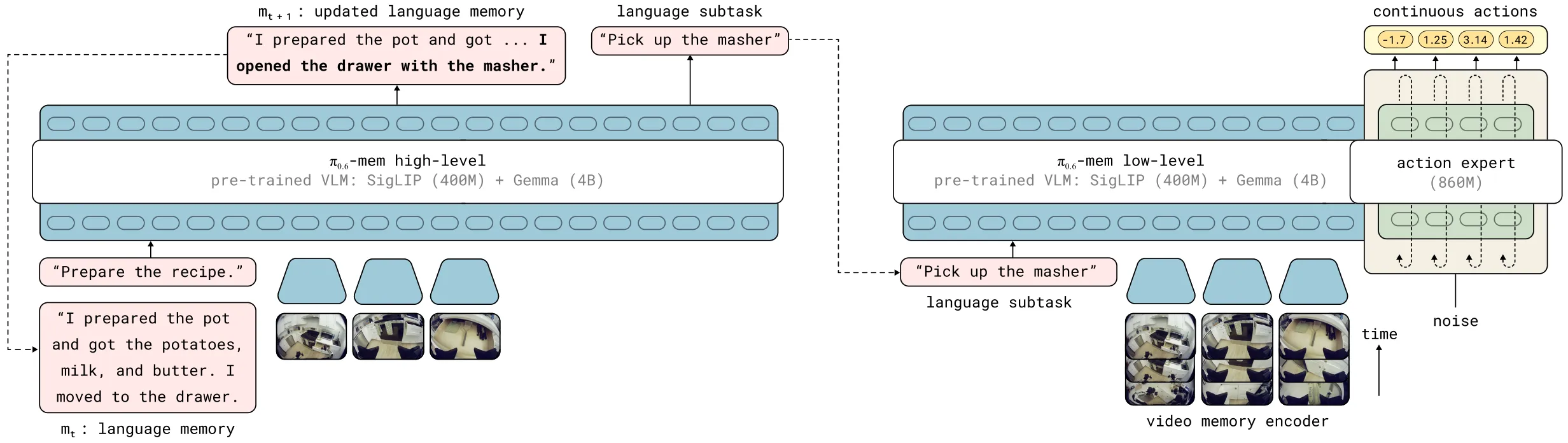
MEM 用视频做短时记忆、文本做长时记忆,目标是支撑 10 分钟量级的长程任务(厨房清理、做三明治)。本身 MEM 还是基于 Pi-0.6 去做的,然后约等于搭建了一个比较 scratch 的 agent memory 框架,一层 ViLA + 视频的输入。在长程任务里 VLA 基本靠 memory 支撑,这种分 horizon 切模态的方式比单一 context window 更合理。
SkillVLA#
双臂单臂技能可左右重组的 Skill 解耦 VLA
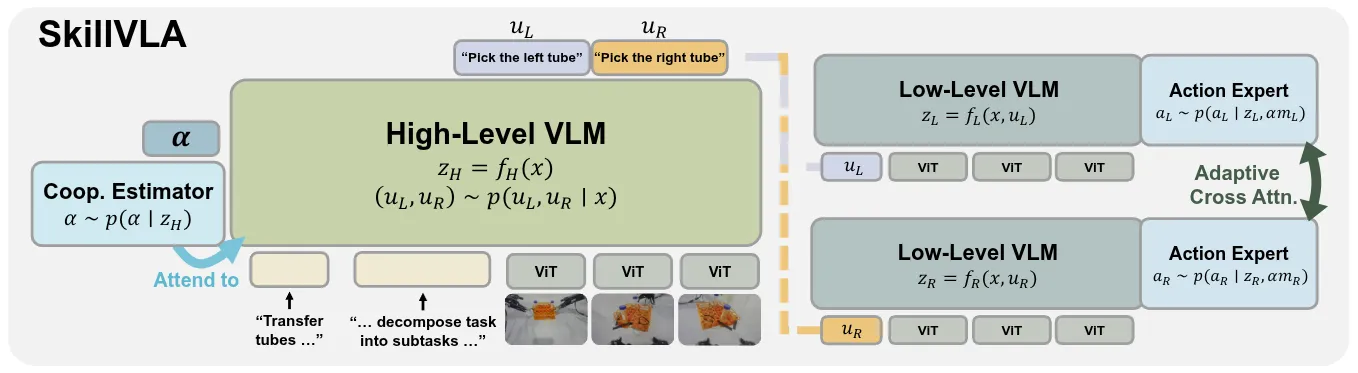
SkillVLA 本身用一种很直接的方式解决了左右臂技能复用以及协作的问题。如图所示,就是先是大脑输出左右手的分别动作,然后交给左右两个 VLA 分别执行,DiT 部分有一个 cross attention。本身可以说是非常直接的做法,但是明显对于多臂或者多机器人协作来说,这个思路似乎拓展性一般。
RoboCasa365#
365 家务任务 + 2500 厨房场景的大规模家用 Benchmark

RoboCasa365 把 RoboCasa 的规模再拉大:365 个家务任务 × 2500 厨房场景,配 600+ 小时人类演示和 1600+ 小时合成数据。不过本身其实任务主要还是 base 任务之间的拼接和组合,不过确实规模很大,并且应该涉及一些 Mobile 的能力,如果需要大规模测试可以看看。
UltraDexGrasp#
2000 万帧合成的双臂灵巧抓取数据集 + 零样本 sim2real
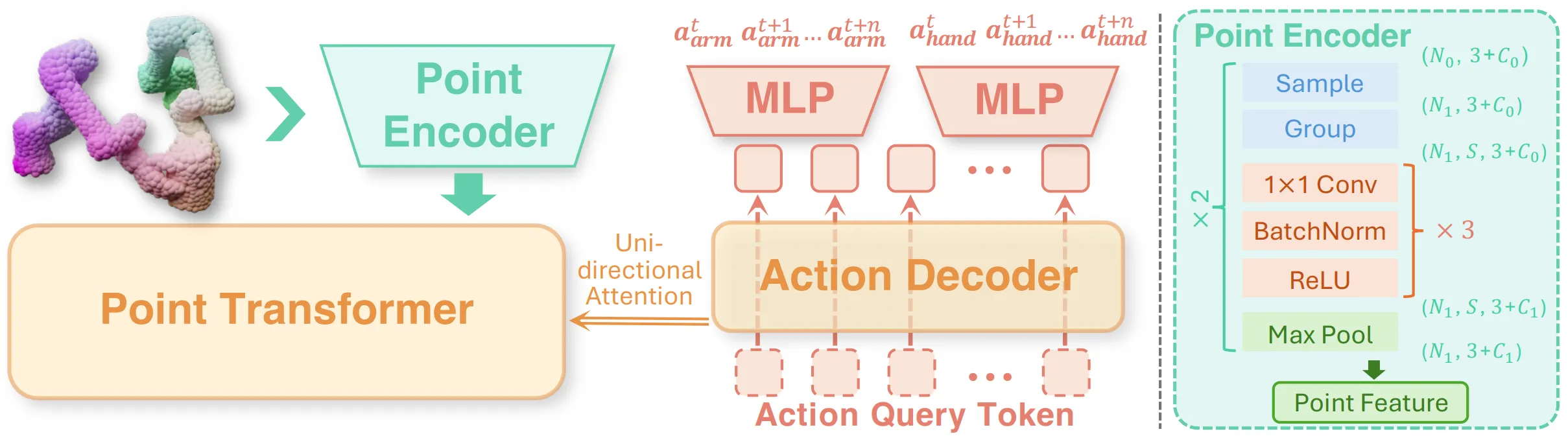
UltraDexGrasp 生成 2000 万帧的双臂灵巧抓取合成数据集,结合 optimization-based 合成和 planning-based demo 生成了这些的数据。对于模型来说如图中所示,就是一个 Point Encoder 然后之后一个 Action Decoder,算是比较正常的一种 Obs to Action 的格式,训出来的策略可以零样本 sim2real。还是比较不错的。
AtomicVLA#
原子技能分解 + SG-MoE 的长程 VLA
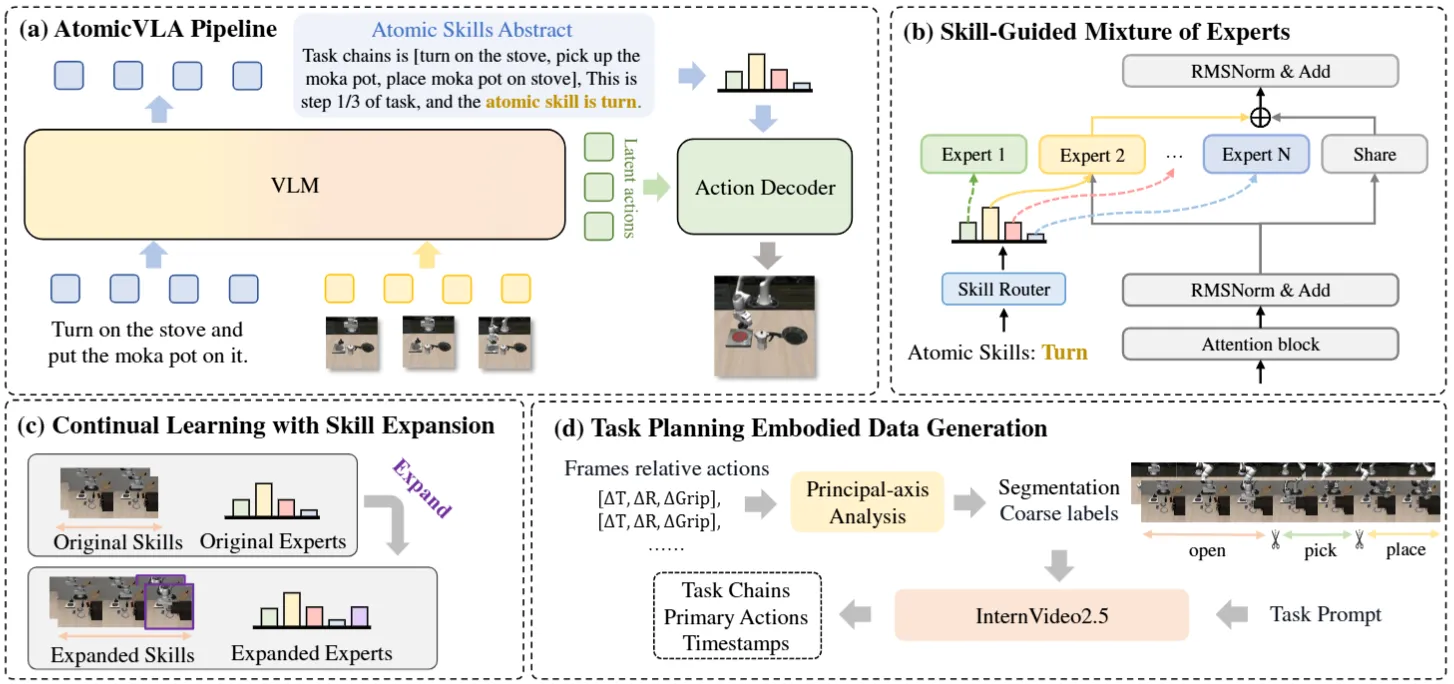
AtomicVLA 把长程任务拆成 atomic skill,用 Skill-Guided MoE 让每个 expert 负责一个原子技能,同时会保持一个 share 的 expert 来 leverage 全部的数据,因此对于新技能的数据就可以通过灵活 routing encoder 做 continual learning。本身问题不大。
AtomVLA#
LLM 拆原子子任务 + 潜空间 WM 给 action chunk 打分的 GRPO
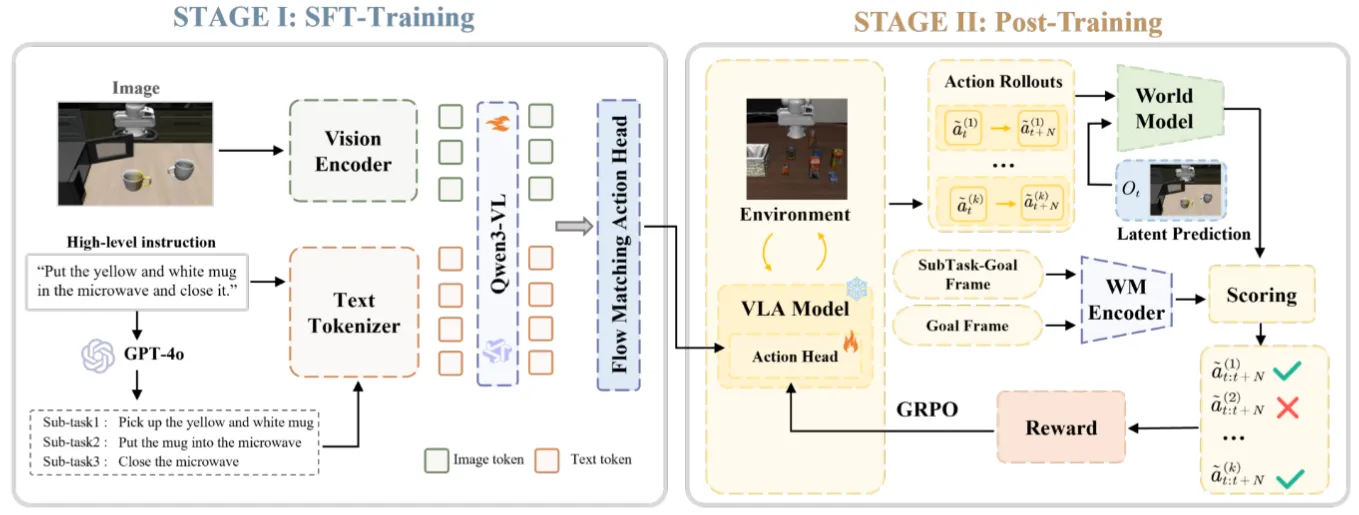
AtomVLA 先进行常规的 SFT,这里面包括了一组 sub goal 在 text 中输入,之后后训练通过 GRPO。获得奖励的做法是用一个预训的 latent world model 对于把候选 action chunk 在 WM 里面进行 step,得到的 latent 和 Sub goal frame 以及 final frame 都求偏差,这样优化 Action 使得其可以偏向生成能抵达 goal frame 的 Action。本身算是一种可以预见的使用 WM 来 offline RL 的做法。
PlayWorld#
机器人自主"play"采集 + 课程学习训接触丰富 World Model
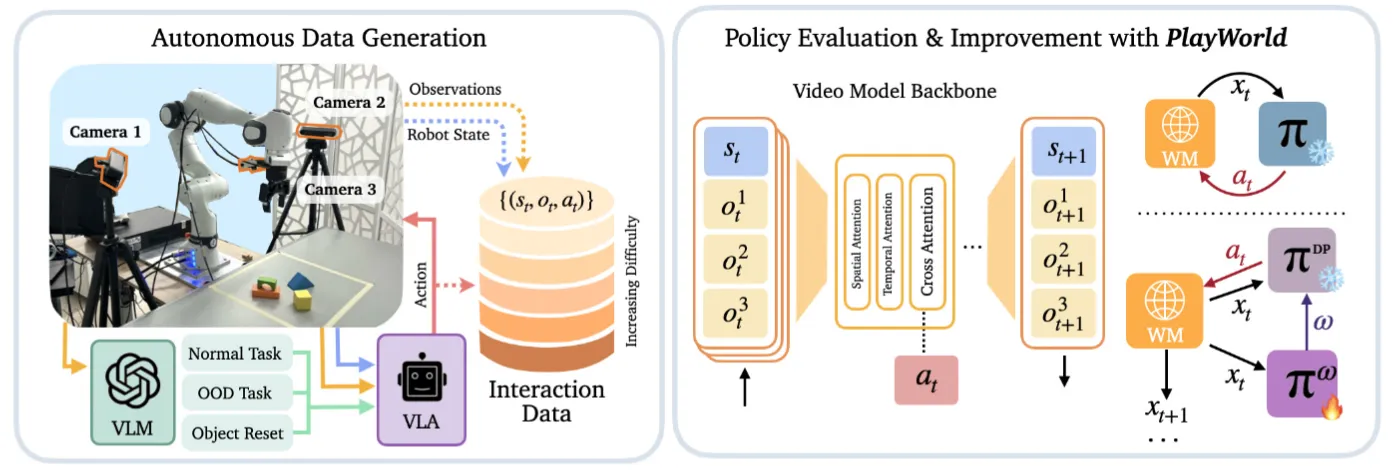
PlayWorld 是比较经典的 WM as simulator 的工作思路,本身也是和我之前提及的一样,这类工作主要的问题是需要覆盖数据的分布,而不是在正常采集的 Demo 分布上训练模型,不然很容易导致 hallucination。这里 Playworld 的做法就是让 VLA 自己探索,然后 rollout 很多的数据来进行训练,之后 SVD 作为视频骨干,以及把数据分难度来课程学习,最后来说效果很不错。总体来说这是我理解下 WM as simulator 的正确思路,自主 rollout 并且避免 bias 导致的幻觉,这很重要。
CORAL#
冻结基模 + 每任务一个 LoRA + 语言决定路由的多任务 VLA
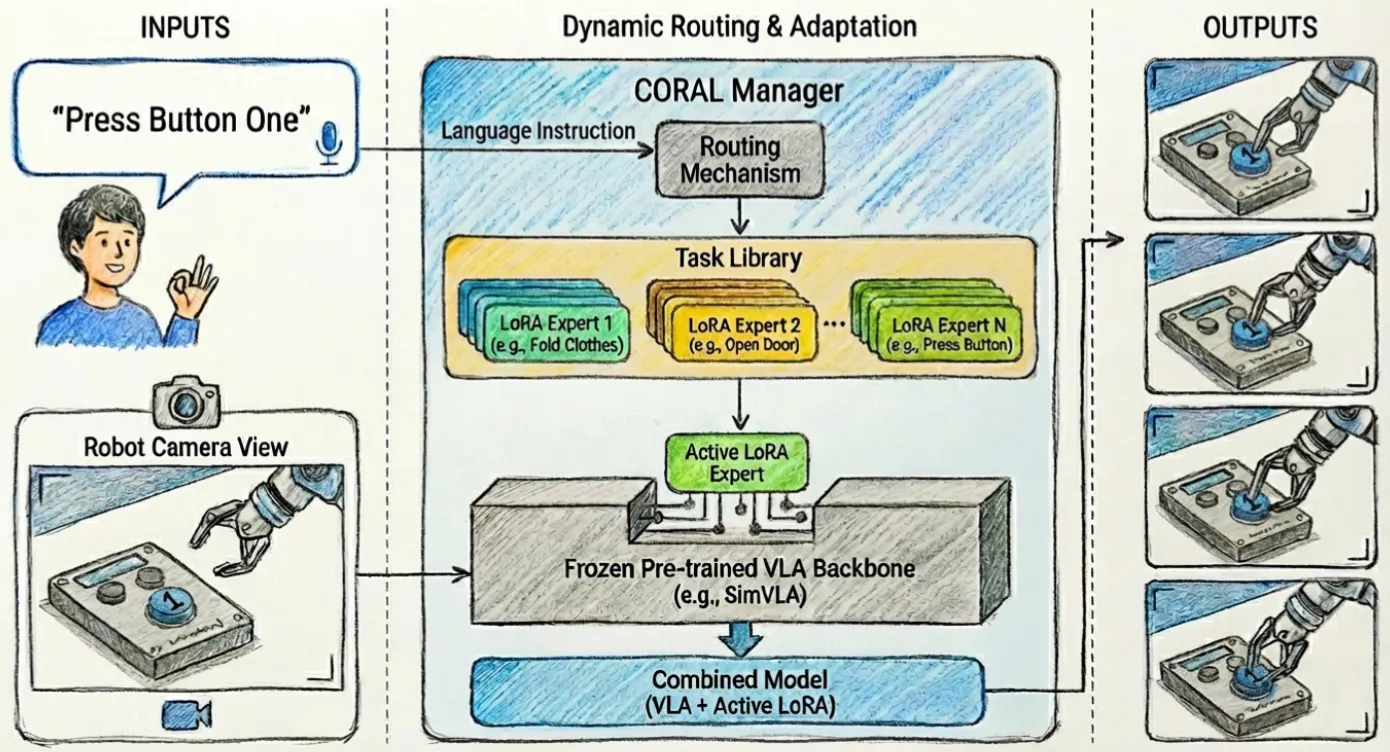
CORAL 就是直接用门控来选择加载不同的 LoRA,从而根据指令来执行不同的任务。不过问题也比较显著,如果说基模不是很强,一些任务只用 LoRA 无法完成,这个时候上限就比较明显了。
DiT4DiT#
抽 Video DiT 中间 denoising 特征作为 Action DiT 条件的双 DiT VLA
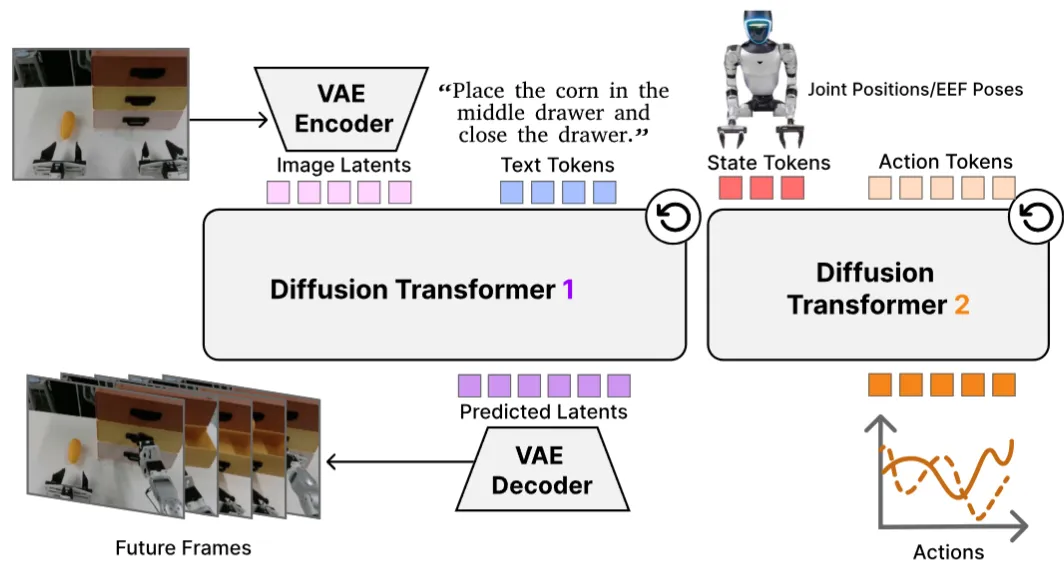
DiT4DiT 使用 Cosmos-Predict2.5-2B 当 Video DiT,然后一个 GR00T-N1 的部分作为 Action DiT,跨注意力把 video 特征和 robot state 喂给 action 端。算是类似于 Pi 的一种设计,在从 VLM-VLA 到 WM-VLA 的范式迁移中是可以预料的。
#
Ego 视频预训 + 机器人后训 + AMO 底层控制的三层 Humanoid VLA
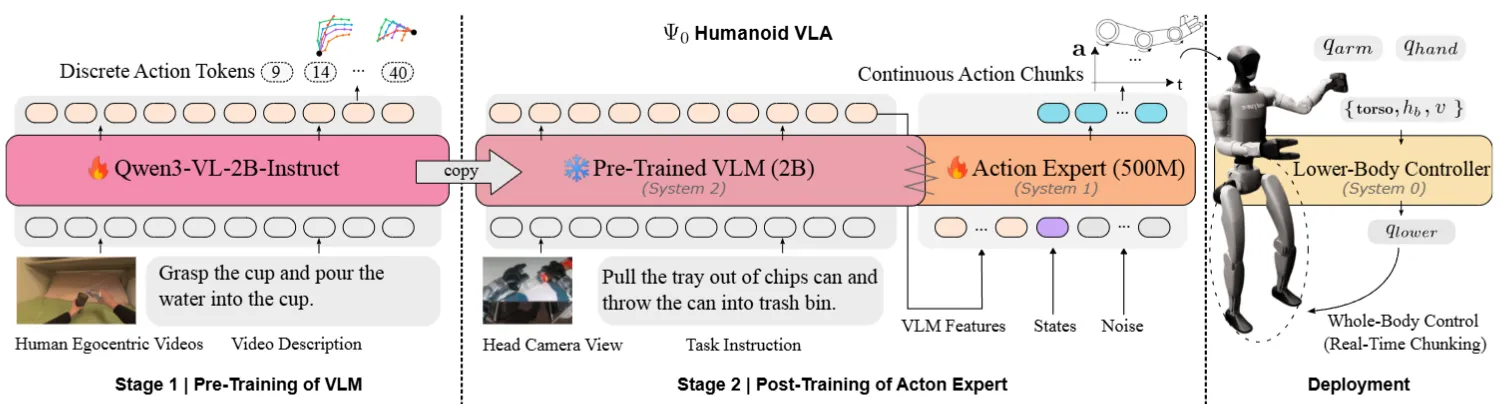
本身使用高质量的 Ego 数据进行了预训练,这里面主要还是训练 VLM;之后在一个 Pi-like 的 VLA 上面进行后训练,之后可以部署在全身的人形机器人上,不过还是使用了一个 System 0,用的是 AM0 下身 RL 的 Controller。本身用 MM-DiT 作为 Actor,然后用了 Training RTC,算是比较合理的一篇 Tech report,意料之中。
TacVLA#
紧凑触觉 token + 接触感知 gating 的 PaliGemma VLA
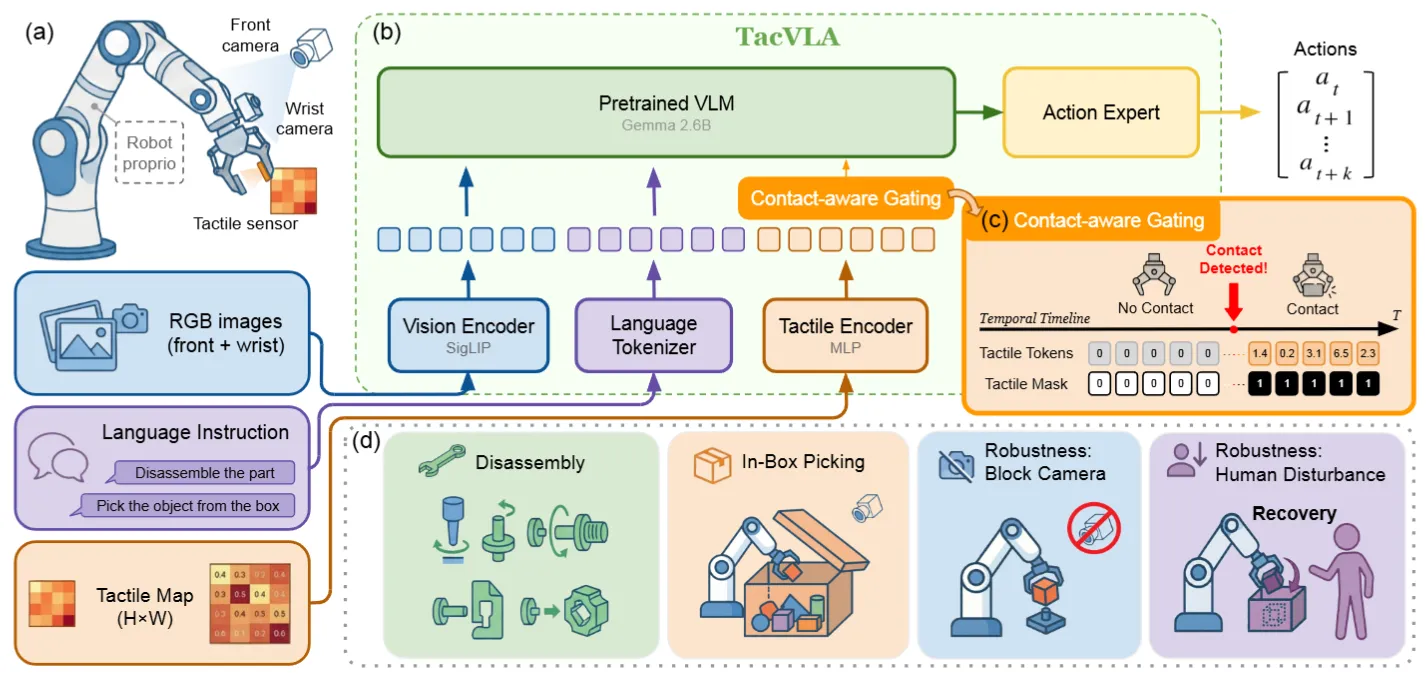
TacVLA 触觉阵列用 MLP + 2D 位置编码压成 36 个紧凑 token,并加一个 contact-aware binary gating,只在检测到接触时才让触觉 token 参与 attention,否则直接 zero out,别的还是比较经典的 Pi-like 设计。本身 TacVLA 的做法还是比较合理的,不过这些用触觉的,还是要用一些令人印象深刻的数据,不然还是不是很 impressive。
ST-VLA#
3D 轨迹 + 平滑空间 mask 作中间表示的层级 VLA
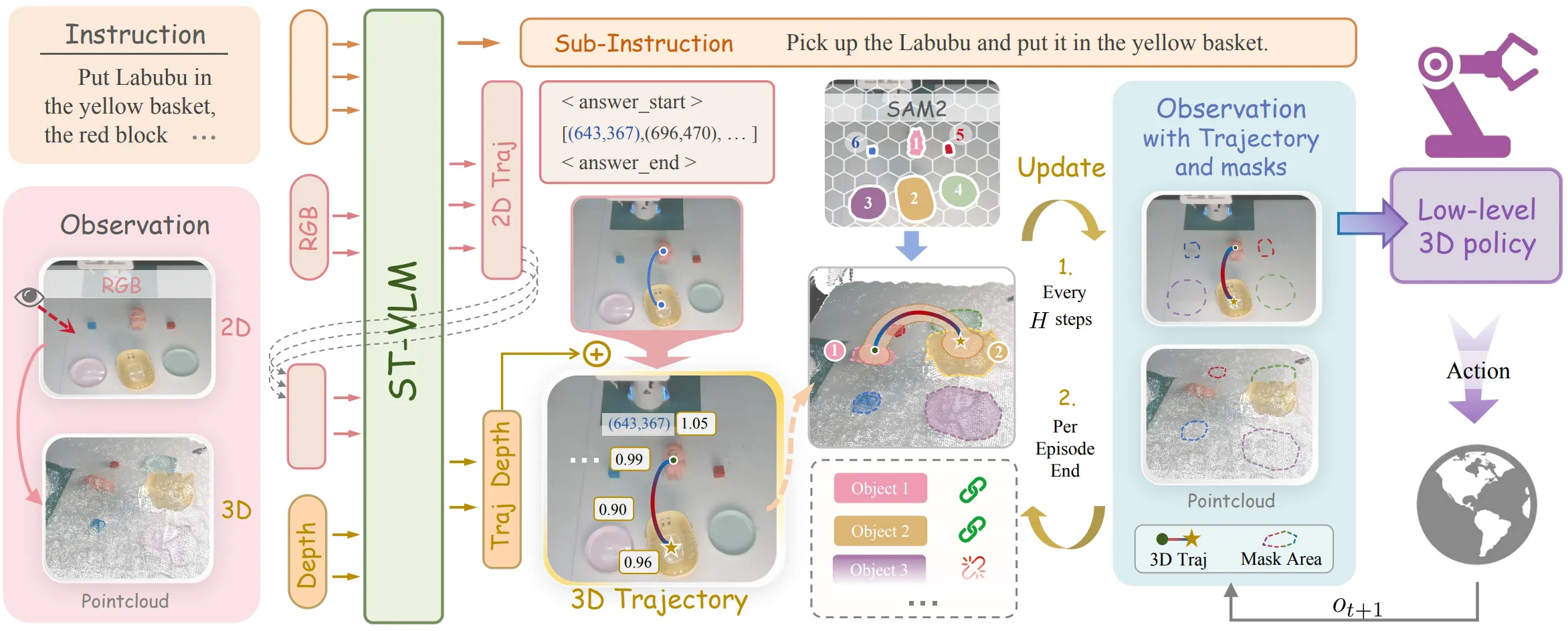
ST-VLA 把 Qwen3-VL-4B 微调成 ST-VLM 出 sub-instruction + 3D trajectory,和 SAM2 的 mask 结合在一起,输入给下游,接专用 3D policy。本身其实和比较古老的比如说 RT-Trajectory 比较类似,稍微做了一些改进,但是并不是狭义 VLA。
ForceVLA2#
Cross-Scale MoE + 力 prompt 引导任务分解的 hybrid 力位 VLA
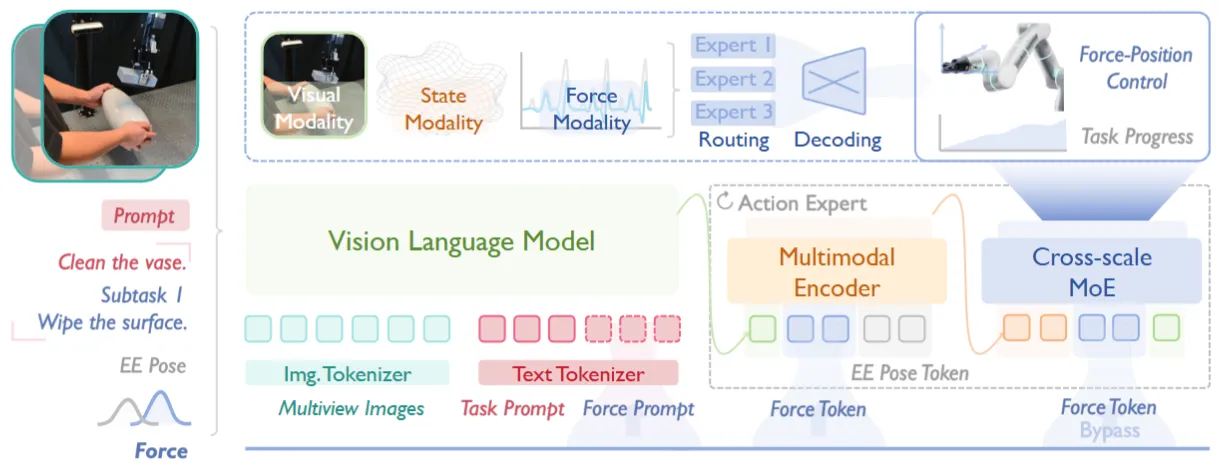
ForceVLA2 长程层用 PaliGemma/SigLIP 接入力 prompt 引导任务分解,短程层用多模态 encoder 吃 6D pose + 6D 力,并且让力信号 bypass 上层 VLM fusion 直接进 reactive 通路,之后输出层是 Cross-Scale MoE 在 visual / state / force 专家间路由,最终走 Flow Matching 出力控信号 + subtask 进度。本身感觉还是挺好的。
MolmoB0T#
Molmo2 + 1.7M 纯合成数据零样本到真机的 VLA
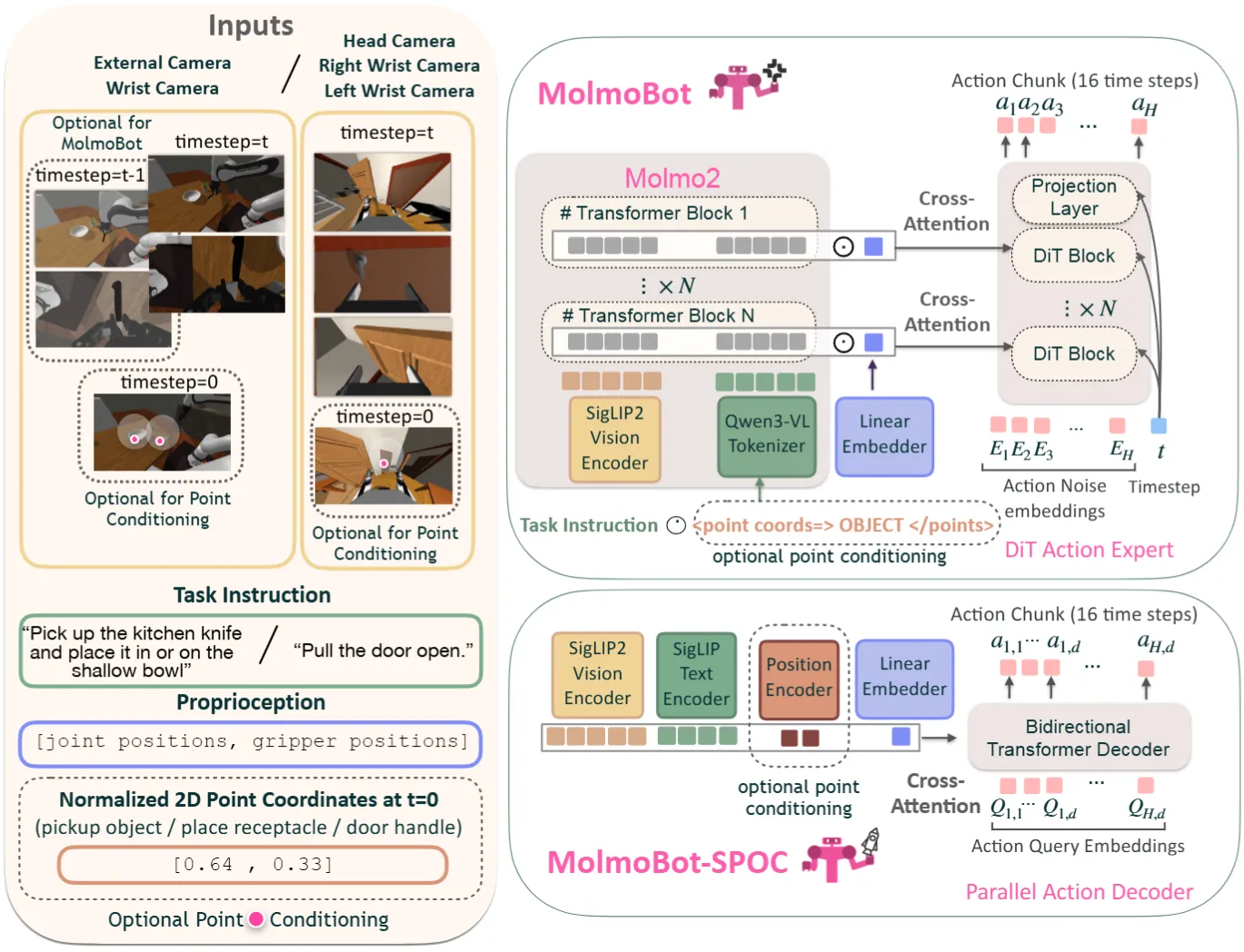
MolmoBot 靠 MolmoBot-Engine 的程序化数据管线生成 170 万条合成轨迹,覆盖 9.4 万个程序化生成房屋 + 1.1 万个独立物体,然后主要提出的架构是 MolmoBot,使用 Molmo2-4B + DiT Flow Matching action head(cross-attn 接 VLM 中间 hidden state),另外的包括 MolmoBot-Pi0 是 Pi 的相同结构,用于消融;以及 MolmoBot-SPOC 是经过一系列 Encoder 之后直接用轻量 Transformer + 离散 quantile bin 动作的模型,给端侧部署。不过显然 Simulation 本身受限于 Scaling 的 Task 以及任务,本身还是比较 Limited 的。
OmniVTA#
21K 真机触觉数据 + 接触演化预测 + 60Hz 闭环的 visuo-tactile 框架
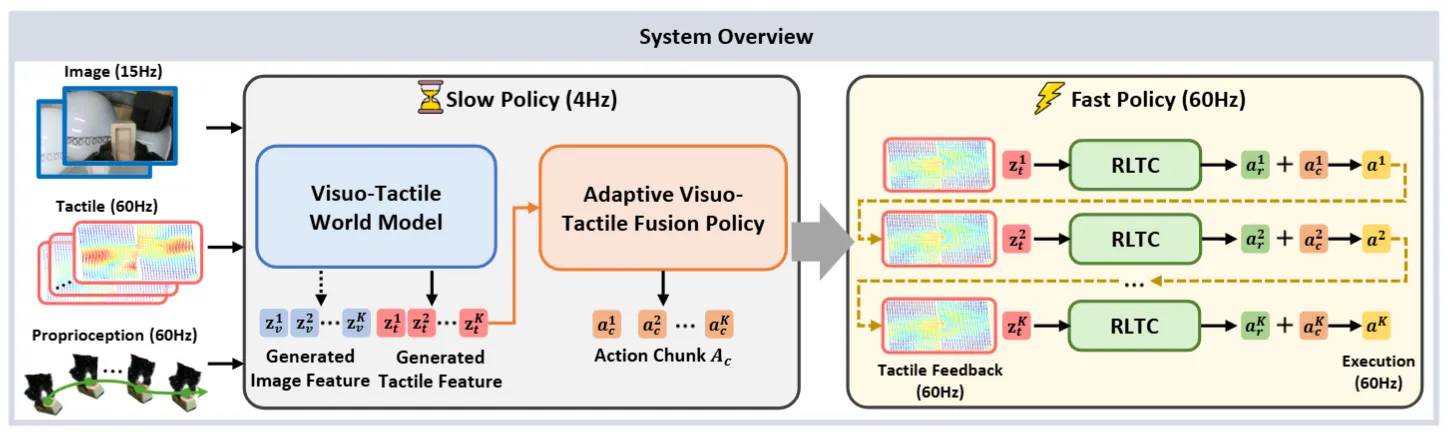
OmniVTA 本身训练了 Tac Encoder,然后对于慢系统的 WM 进行的是同时预测 Visual 和 Tac,这其实和之前的 ViTacFormer 的做法比较类似,之后接 DiT。对于下游的快系统,做了一个小模型,对于慢系统的动作,输入触觉进行快速反馈纠正。本身还可以。